大模型训练
MindFormers
MindSpore Transformers套件的目标是构建一个大模型训练、微调、评估、推理、部署的全流程开发套件: 提供业内主流的Transformer类预训练模型和SOTA下游任务应用,涵盖丰富的并行特性。期望帮助用户轻松的实现大模型训练和创新研发。
MindSpore Transformers套件基于MindSpore内置的并行技术和组件化设计,具备如下特点: 一行代码实现从单卡到大规模集群训练的无缝切换;
提供灵活易用的个性化并行配置;
能够自动进行拓扑感知,高效地融合数据并行和模型并行策略;
一键启动任意任务的单卡/多卡训练、微调、评估、推理流程;
支持用户进行组件化配置任意模块,如优化器、学习策略、网络组装等;
提供Trainer、pipeline、AutoClass等高阶易用性接口;
提供预置SOTA权重自动下载及加载功能;
支持人工智能计算中心无缝迁移部署;
当前支持的模型列表查询,每个模型均有单独的使用说明。
1.基础准备
建议使用最新tag的镜像:镜像获取
版本匹配关系:MindFormers r1.2.0
数据集获取:预训练-Wikitext-103 / 微调-alpaca
2.套件安装
chmod +x mindformers.sh使脚本可执行bash mindformers.sh一键安装
3.单机多卡
3.1 数据预处理
1.1 Wikitext-103 数据预处理
执行如下命令,生成Mindrecord格式数据集
python research/qwen1_5/qwen1_5_preprocess.py \
--dataset_type 'wiki' \
--input_glob /{数据集路径}/wiki.train.tokens \
--vocab_file /{权重文件路径}/Qwen1.5-7B/vocab.json \
--merges_file /{权重文件路径}/Qwen1.5-7B/merges.txt \
--seq_length 32768 \
--output_file /{预处理后数据集输出路径}/wiki.mindrecord
dataset_type: 预处理数据类型input_glob: 输入下载后wiki.train.tokens的文件路径vocab_file: vocab.json文件路径(huggingface权重文件中)merges_file: merges.txt文件路径(huggingface权重文件中)seq_length: 输出数据的序列长度output_file: 输出文件的保存路径
1.2 alpaca 数据预处理
首先执行如下命令,将原始数据集转换为指定格式
python research/qwen1_5/alpaca_converter.py \
--data_path /{数据集路径}/alpaca_data.json \
--output_path /{转换格式后数据集输出路径}/alpaca-data-messages.json
data_path:输入下载的文件路径output_path:输出文件的保存路径
得到转换格式的数据集后执行如下命令,进行数据预处理和Mindrecord数据生成
python research/qwen1_5/qwen1_5_preprocess.py \
--dataset_type 'qa' \
--input_glob /{转换格式后数据集输出路径}/alpaca-data-messages.json \
--vocab_file /{权重文件路径}/Qwen1.5-7B/vocab.json \
--merges_file /{权重文件路径}/Qwen1.5-7B/merges.txt \
--seq_length 4096 \
--output_file /{预处理后数据集输出路径}/alpaca-messages.mindrecord
3.2 权重转换
注: 请安装convert_weight.py依赖包。
pip install torch transformers>=4.37.2 transformers_stream_generator einops accelerate
3.2.1 torch权重转mindspore权重
将huggingface的权重转换为完整的ckpt权重。
python research/qwen1_5/convert_weight.py \
--torch_ckpt_dir /{权重文件路径}/Qwen1.5-7B \
--mindspore_ckpt_path /{权重转换输出路径}/qwen1.5_7b.ckpt
torch_ckpt_dir:预训练权重文件所在的目录, 此参数必须mindspore_ckpt_path:转换后的输出文件存放路径
如遇报错:
ImportError: {报错文件路径}: cannot allocate memory in static TLS block,使用LD_PRELOAD环境变量指定对报错的单个或多个库文件进行优先加载:执行Export LD_PRELOAD=$LD_PRELOAD:{报错文件路径}
3.2.2 mindspore权重转torch权重
在生成mindspore权重之后如需使用torch运行,可根据如下命令转换:
python research/qwen1_5/convert_reversed.py \
--mindspore_ckpt_path /{mindspore权重路径}/qwen1.5_7b.ckpt \
--torch_ckpt_path /{权重转换输出路径}/your.bin
mindspore_ckpt_path:待转换的mindspore权重路径torch_ckpt_path:转换后的输出文件存放路径
3.3 预训练
以qwen1_5-7b单机8卡预训练任务为例,执行分布式启动脚本
requirements.txt以外额外需要安装的依赖库
pip install decorator attrs sympy
pip install mindspore==2.3.0
启动预训练
bash scripts/msrun_launcher.sh "run_mindformer.py \
--config research/qwen1_5/pretrain_qwen1_5_7b.yaml \
--load_checkpoint /{mindspore权重路径}/qwen1.5_7b.ckpt \
--train_dataset_dir /{预处理后数据集输出路径}/wiki.mindrecord \
--run_mode train" 8
3.4 全参微调
设置如下环境变量:
export MS_ASCEND_CHECK_OVERFLOW_MODE=INFNAN_MODE
# 如出现OOM需要配置:
export ENABLE_CELL_RESUSE=1 # 打开内存复用
export MS_GE_ATOMIC_CLEAN_POLICY=1 # 打开内存优化
启动微调任务
bash scripts/msrun_launcher.sh "research/qwen1_5/run_qwen1_5.py \
--config research/qwen1_5/finetune_qwen1_5_7b.yaml \
--load_checkpoint /{mindspore权重路径}/qwen1.5_7b.ckpt \ 用的是上面torch转mindspore的权重
--auto_trans_ckpt True \ 是否开启自动在线权重切分或转换
--train_dataset /path/alpaca.mindrecord \
--run_mode finetune" 8
多机多卡分布式训练
先把代码目录、预处理数据、ckpt权重转换文件上传到obs桶里
obs桶操作如下:
./obsutil config -i=ak -k=sk -e=endpoint使用永久AK、SK进行初始化配置
./obsutil/obsutil cp 桶里被复制文件路径 目标文件夹路径 -r -f 复制桶里的文件到目标路径,如果是复制文件夹,后面加-r -f,此命令可以通过对调目录把在notebook里的文件夹上传到obs
modelArts上创建多机训练作业
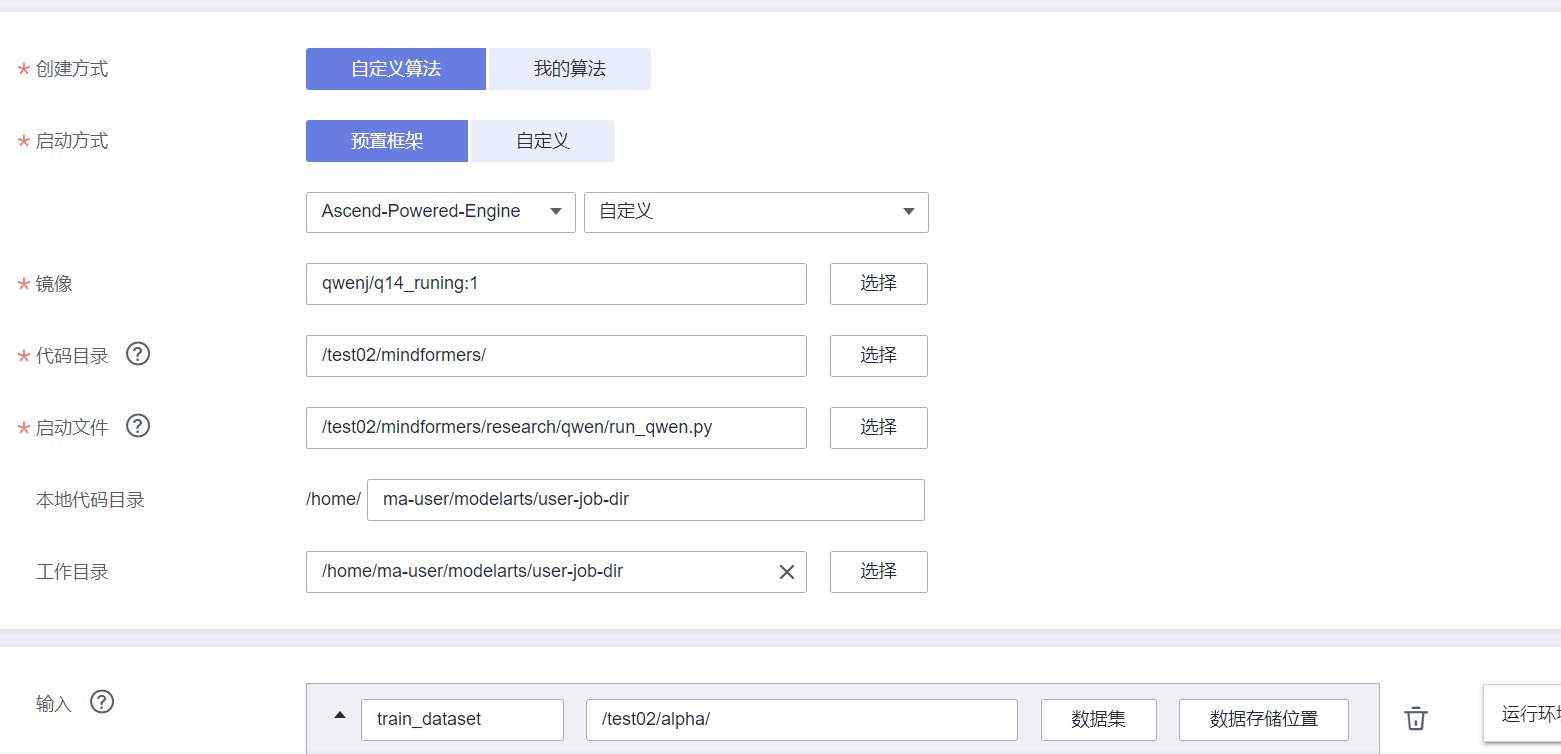
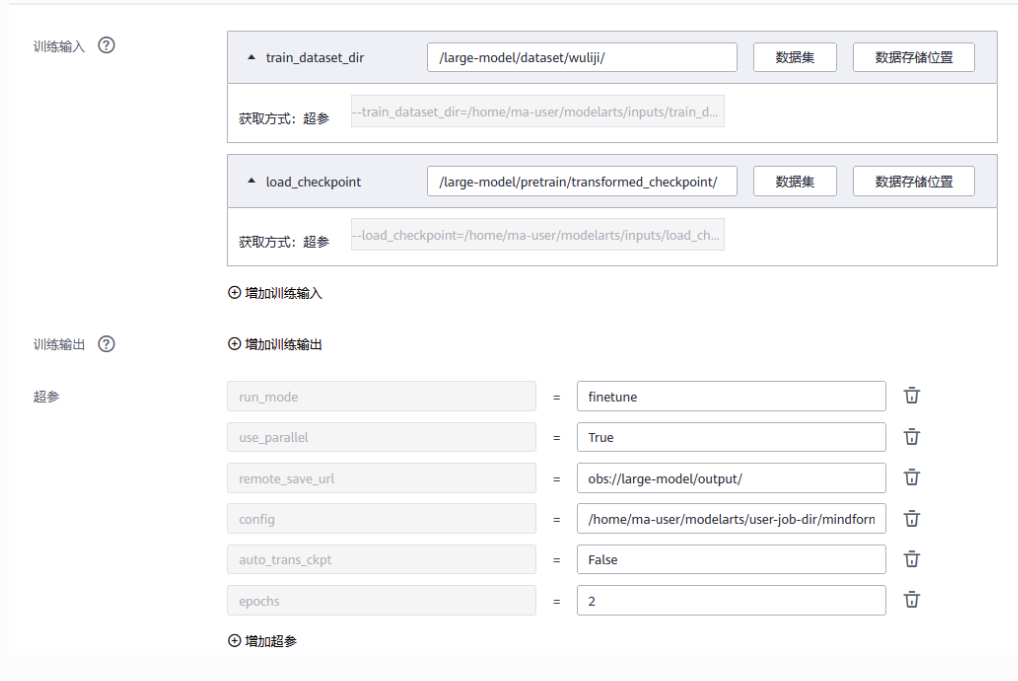
参数说明
config: 配置文件路径
run_mode: 运行模式, 预训练时设置为train
train_data: 训练数据集文件夹路径
merges_file: 词表文件merges.txt路径
vocab_file: 词表文件vocab.json路径
auto_trans_ckpt设成true会根据当前pp/mp/dp自动切分,生成strategy和transformed_checkpoint两个文件夹,将这两个文件夹重新保存到其他目录。
参考文档链接
MindSpeed-LLM
1.MindSpeed-LLM简介
MindSpeed-LLM,原仓名ModelLink,作为昇腾大模型训练框架,旨在为华为 昇腾芯片 提供端到端的大语言模型训练方案, 包含分布式预训练、分布式指令微调、分布式偏好对齐以及对应的开发工具链。
注 : 原包名 modellink 更改为 mindspeed_llm
2.镜像准备
从下面网址里获取最新镜像链接并且注册: 镜像地址
镜像注册指导:镜像注册
3.套件安装
安装mindspeedllm:
从下面网址里获取最新安装脚本: 脚本地址
进入镜像,执行安装脚本:bash modellink.sh
debug参考:
4.准备数据集
转换数据集
cd /home/ma-user/work/MindSpeed-LLM
python preprocess_data.py \
--input /home/ma-user/work/MindSpeed-LLM/dataset/Alpaca_train.json \
--tokenizer-name-or-path /home/ma-user/work/Qwen2.5-14B/ \
--output-prefix ./dataset/alpaca/ \
--handler-name GeneralInstructionHandler \
--tokenizer-type PretrainedFromHF \
--workers 4 \
--log-interval 1000 \
5.将权重从 huggingface 格式转化为 megatron 格式
cd /home/ma-user/work/MindSpeed-LLM
python tools/checkpoint/convert_ckpt.py \
--model-type GPT \
--loader llama2_hf \
--saver megatron \
--target-tensor-parallel-size 2 \
--target-pipeline-parallel-size 2 \
--make-vocab-size-divisible-by 16 \
--load-dir /home/ma-user/work/Qwen2.5-14B/ \
--save-dir ./model_weights/Qwen2.5-14B-tp2-pp2/ \
--tokenizer-model /home/ma-user/work/Qwen2.5-14B/tokenizer.json \
--add-qkv-bias \
--params-dtype bf16
6.开启训练(8卡)
修改训练脚本/home/ma-user/work/MindSpeed-LLM/examples/qwen15/pretrain_qwen15_14b_ptd.sh:
export MEMORY_FRAGMENTATION=1;export MULTI_STREAM_ME=1;export PYTORCH_NPU_ALLOC_CONF="expandable_segments:False,max_split_size_mb:21";
CKPT_LOAD_DIR="/home/ma-user/work/MindSpeed-LLM/model_weights/Qwen2.5-14B-v0.1-tp2-pp2"
CKPT_SAVE_DIR="/home/ma-user/work/MindSpeed-LLM/model_weights/qwen_trained_ckpts"
DATA_PATH="/home/ma-user/work/MindSpeed-LLM/finetune_dataset/alpaca/"
TOKENIZER_PATH="/home/ma-user/work/Qwen2.5-14B"
GPT_ARGS="
--tensor-model-parallel-size ${TP} \
--pipeline-model-parallel-size ${PP} \
--sequence-parallel \
--ffn-hidden-size 13824 \
--group-query-attention \
--num-query-groups 8 \
--rotary-base 1000000 \
--norm-epsilon 1e-5 \
--num-layers 48 \
--hidden-size 5120 \
--transformer-impl local \
--num-attention-heads 40 \
--load ${CKPT_LOAD_DIR} \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path ${TOKENIZER_PATH} \
--seq-length 1024 \
--max-position-embeddings 131072 \
--micro-batch-size 1 \
--global-batch-size 32 \
--make-vocab-size-divisible-by 1 \
--padded-vocab-size 152064 \
--rotary-base 1000000 \
--lr 1.25e-6 \
--train-iters 5000 \
--lr-decay-style cosine \
--untie-embeddings-and-output-weights \
--disable-bias-linear \
--attention-dropout 0.0 \
--init-method-std 0.01 \
--hidden-dropout 0.0 \
--position-embedding-type rope \
--normalization RMSNorm \
--swiglu \
--use-flash-attn \
--use-fused-rmsnorm \
--use-fused-rotary-pos-emb \
--use-rotary-position-embeddings \
--use-fused-swiglu \
--use-mc2 \
--no-masked-softmax-fusion \
--attention-softmax-in-fp32 \
--min-lr 1.25e-7 \
--weight-decay 1e-1 \
--lr-warmup-fraction 0.01 \
--clip-grad 1.0 \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--add-qkv-bias \
--initial-loss-scale 4096 \
--no-gradient-accumulation-fusion \
--no-load-optim \
--no-load-rng \
--seed 42 \
--bf16 \
--load ${CKPT_LOAD_DIR} \
--finetune \
--is-instruction-dataset \
--tokenizer-not-use-fast \
--use-distributed-optimizer
"
参数解释
--load ${CKPT_LOAD_DIR}解释: 从指定的目录 (
${CKPT_LOAD_DIR}) 加载预训练模型或检查点 (checkpoint)。用途: 通常用于在训练或推理过程中加载已经训练好的模型权重,以便继续训练或进行推理。
--finetune解释: 启用微调 (fine-tuning) 模式。
用途: 在微调模式下,模型会基于预训练的权重进行进一步的训练,通常用于特定任务的适应性调整。
--is-instruction-dataset解释: 指示数据集是基于指令的 (instruction-based)。
用途: 用于指定数据集的类型,通常在处理需要遵循特定指令的任务时使用,例如自然语言理解或生成任务。
--tokenizer-not-use-fast解释: 禁用快速分词器 (fast tokenizer)。
用途: 默认情况下,许多模型使用快速分词器以提高效率,但在某些情况下可能需要使用原始的分词器实现。
--use-distributed-optimizer解释: 启用分布式优化器。
用途: 在分布式训练环境中使用,优化器会在多个设备或节点之间协同工作,以提高训练效率和性能。 额外的,添加显存优化相关环境变量:
环境变量和配置解释
export MEMORY_FRAGMENTATION=1解释: 启用内存碎片化检测或优化。
用途: 该变量可能用于调试或优化内存分配,特别是在需要检测或减少内存碎片化的情况下。值为
1表示启用相关功能。
export MULTI_STREAM_ME=1解释: 启用多流内存分配或管理。
用途: 该变量可能用于支持多流处理或并行计算的内存管理。值为
1表示启用多流内存分配功能。
export PYTORCH_NPU_ALLOC_CONF="expandable_segments:False,max_split_size_mb:21"解释: 配置 PyTorch NPU 内存分配策略。
用途:
expandable_segments:False: 不允许内存段动态扩展。max_split_size_mb:21: 设置内存分配时的最大分割大小为 21 MB,用于控制内存分配的粒度。
场景: 这些配置通常用于优化 PyTorch 在 NPU(如华为 Ascend NPU)上的内存分配策略,以提高性能或避免内存不足的问题。
训练命令:
bash /home/ma-user/work/MindSpeed-LLM/examples/qwen15/train_qwen25_14b.sh
7.转回HF权重(8卡)
转回HF权重
必须输出在原HF的路径下
python tools/checkpoint/convert_ckpt.py \
--model-type GPT \
--loader megatron \
--saver megatron \
--save-model-type save_huggingface_llama \
--load-dir /home/ma-user/work/MindSpeed-LLM/model_weights/Qwen2.5-14B-v0.1-tp2-pp2/qwen_trained_ckpts \
--target-tensor-parallel-size 1 \
--target-pipeline-parallel-size 1 \
--add-qkv-bias \
--save-dir /home/ma-user/work/Qwen2.5-14B/ ## <-- 需要填入原始HF模型路径,新权重会存于./model_from_hf/qwen15-4b-hf/mg2hg/
参考链接:
多机流程:
MindSpeedLLM多机流程
1️.获取镜像
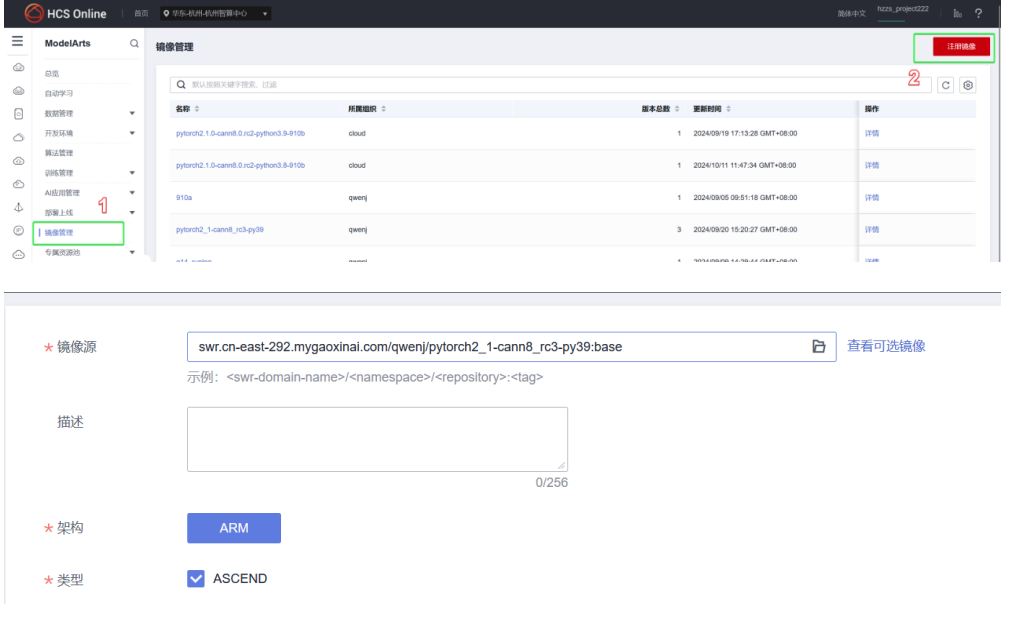
镜像地址:
swr.cn-east-292.mygaoxinai.com/qwenj/pytorch2_1-cann8_rc3-py39:base
2️.创建 Notebook
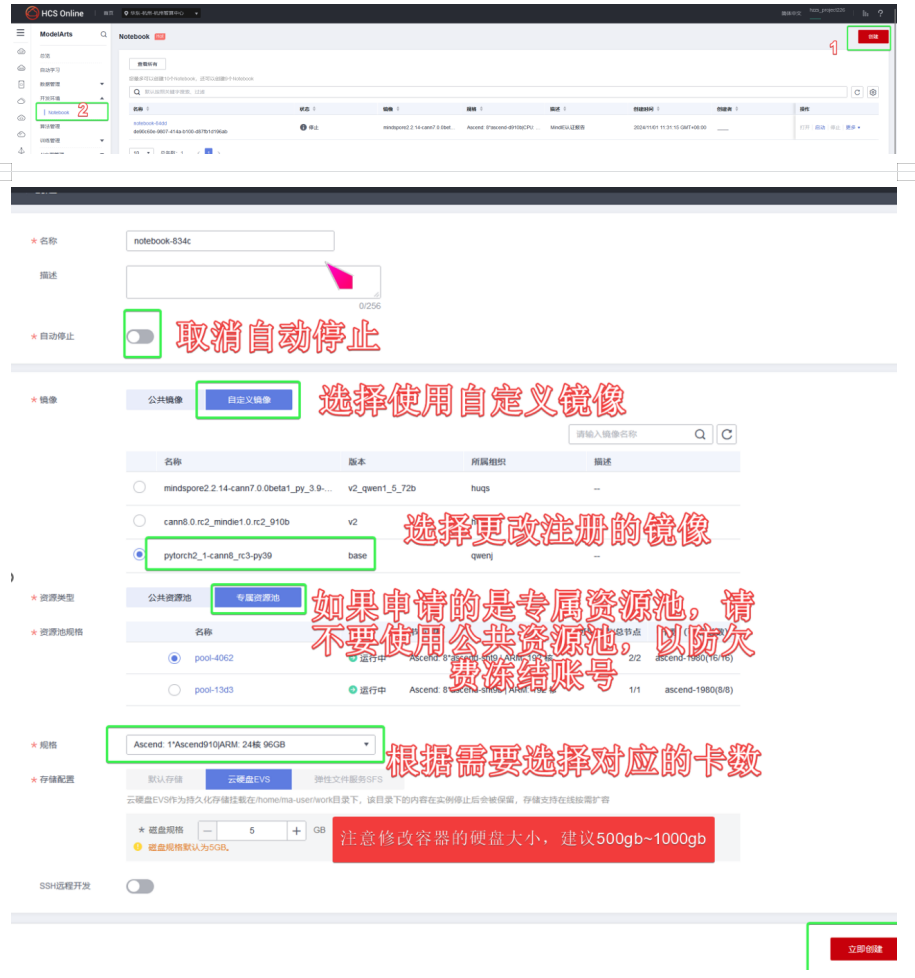
3️.数据获取
单机获取文件:
使用Ctrl+C复制后,粘贴到本地桌面 (Ctrl+V)。Linux命令工具 Obsutil:
Obsutil 是用于与云存储服务交互的命令行工具。 点击下面链接下载:
配置登录:
./obsutil config -i=${OBSAK} -k=${OBSSK} -e=obs.cn-east-292.mygaoxinai.com
数据获取命令:
## 下载单个文件
./obsutil cp source_file target_file
## 同步文件夹
./obsutil sync source_folder target_folder
## 获取代码库
./obsutil sync obs://modellink-cloud/AscendSpeed/ ./AscendSpeed
获取模型原始权重:
可通过 ModelScope 或 HF-Mirror 等网站。
4️.数据上传 ⬆
创建桶:
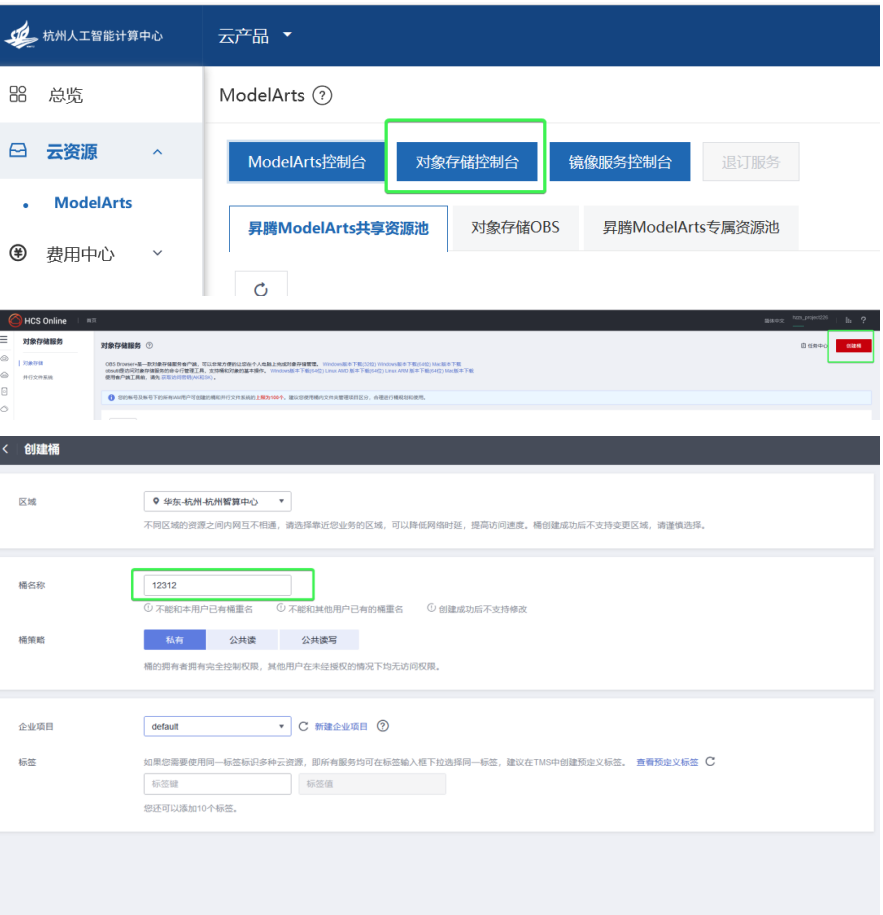
上传命令:
## 假设桶名为 work,代码路径为 ~/work/AscendSpeed,模型路径为 ~/work/models
./obsutil sync ~/work/AscendSpeed obs://work/AscendSpeed
./obsutil sync ~/work/models obs://work/models
5️.保存镜像
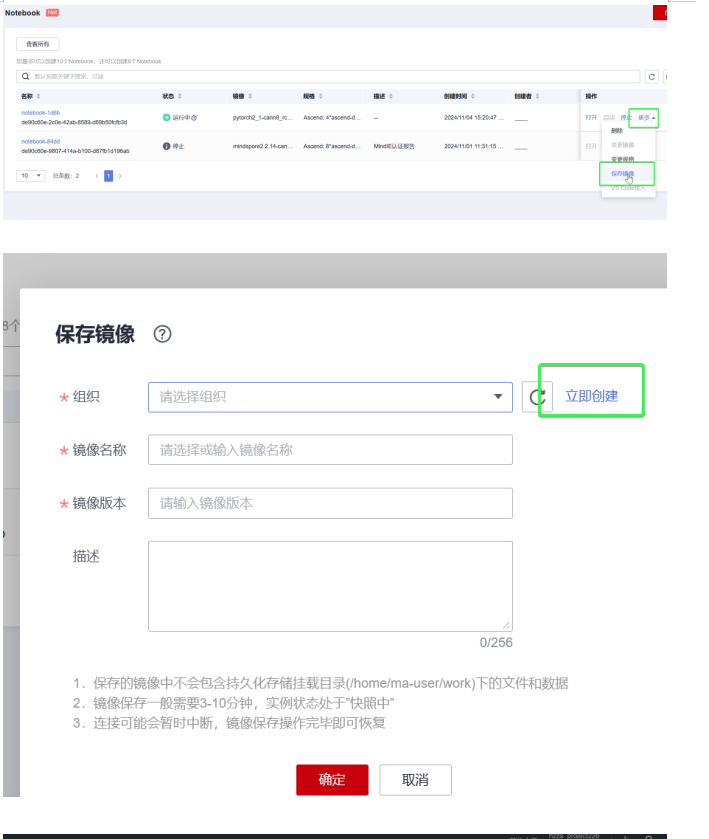
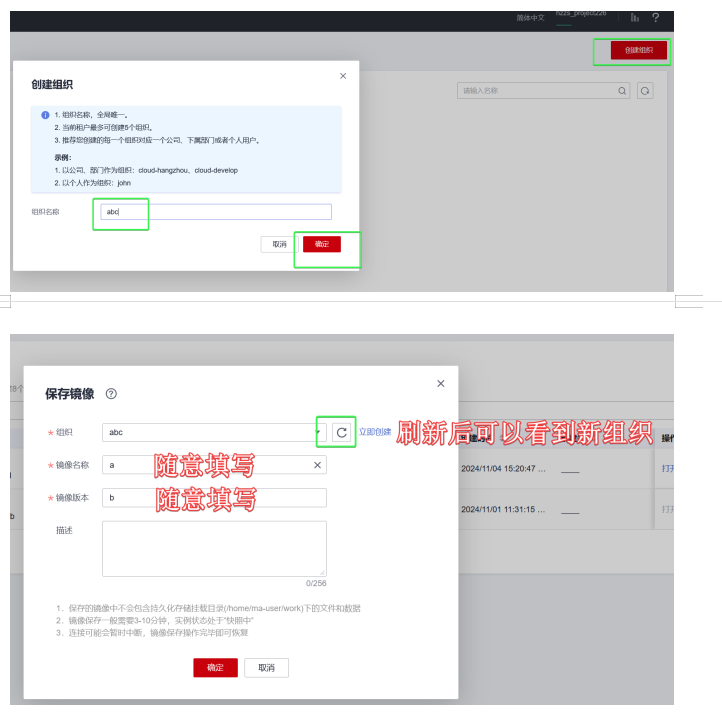
6️.创建训练作业
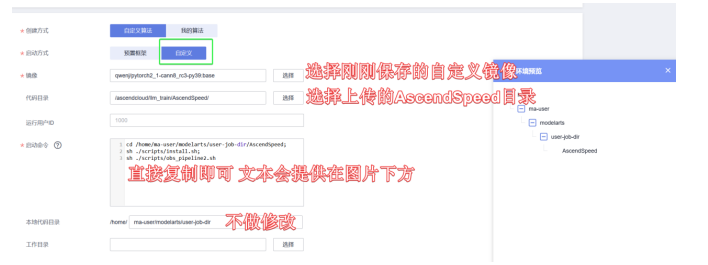
启动命令:
cd /home/ma-user/modelarts/user-job-dir/AscendSpeed
sh ./scripts/install.sh
sh ./scripts/obs_pipeline2.sh
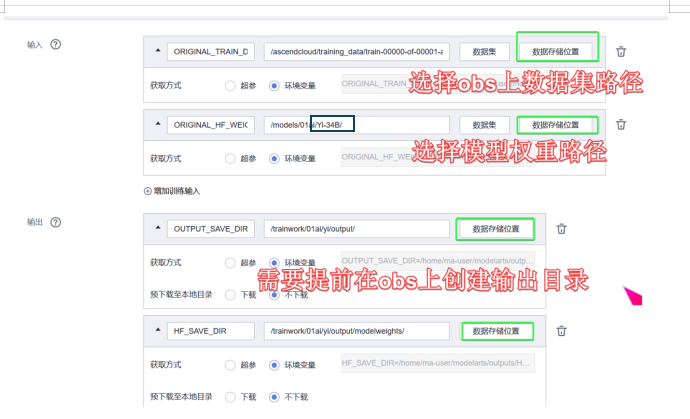
输入变量名:
ORIGINAL_TRAIN_DATA_PATH=
ORIGINAL_HF_WEIGHT=
输出变量名:
OUTPUT_SAVE_DIR=
HF_SAVE_DIR=
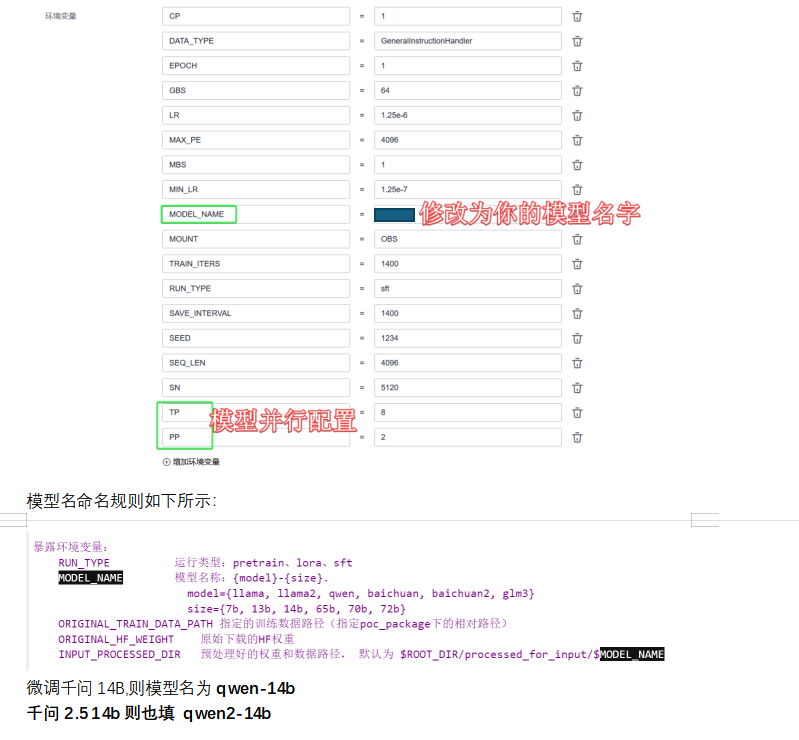
模型命名规则:
微调 千问14B, 则模型名为:
qwen-14b
微调 千问2.5 14B, 则模型名为:
qwen2-14b
训练配置参数示例:
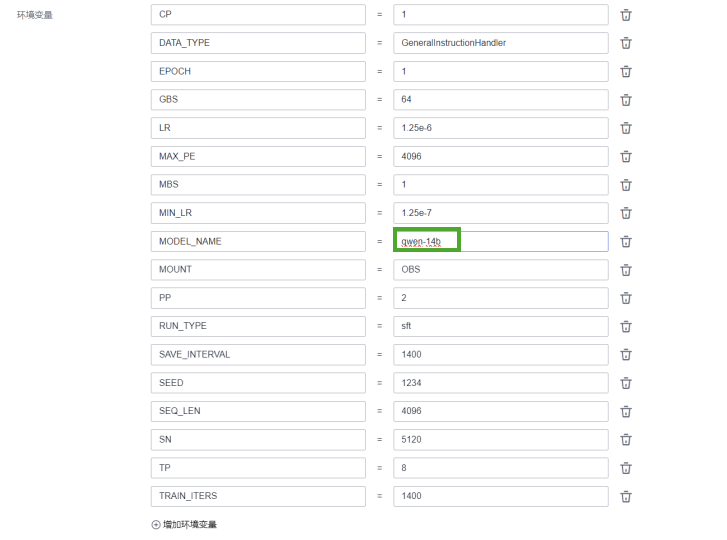
Megatron训练参数解释
以下是常用的 Megatron-LM 训练参数及其含义解析:
参数说明
| 参数名 | 含义 | 示例值 |
|---|---|---|
CP |
检查点 (Checkpoint) 数: 指训练过程中保存的模型分片数量。 | 1 |
DATA_TYPE |
数据处理类型: 指定输入数据的处理逻辑或预处理模块。 | GeneralInstructionHandler |
EPOCH |
训练轮次 (Epoch): 数据集被完整遍历的次数。 | 1 |
GBS |
全局批量大小 (Global Batch Size): 多机总的 batch size(所有设备上累加)。 | 64 |
LR |
初始学习率 (Learning Rate): 优化器的学习率初始值。 | 1.25e-6 |
MAX_PE |
最大位置编码 (Max Position Encoding): 序列的最大长度,通常等于 SEQ_LEN。 |
4096 |
MBS |
微批量大小 (Micro Batch Size): 每张卡上的局部 batch size,GBS = MBS × 卡数 × 梯度累积步数。 |
1 |
MIN_LR |
最小学习率 (Minimum Learning Rate): 学习率的下限值,用于学习率调度器。 | 1.25e-7 |
MODEL_NAME |
模型名称: 训练生成的模型名称,用于保存或管理模型文件。 | yi-34b |
MOUNT |
挂载类型 (Mount Type): 数据存储类型,通常是对象存储(如 OBS 或其他存储服务)。 |
OBS |
TRAIN_ITERS |
训练迭代次数: 总的训练步数,等于 EPOCH × 数据集大小 / GBS。 |
1400 |
RUN_TYPE |
运行模式: 例如 sft 表示微调,pretrain 表示预训练。 |
sft |
SAVE_INTERVAL |
保存间隔 (Save Interval): 每隔多少步保存一次模型权重。 | 1400 |
SEED |
随机种子 (Seed): 用于随机数生成器的初始化,确保训练的可重复性。 | 1234 |
SEQ_LEN |
序列长度 (Sequence Length): 训练数据的最大 token 长度。 | 4096 |
SN |
模型隐藏层维度 (Hidden Size): 通常表示 Transformer 模型的隐层维度(如 SN=5120 表示 5120 维)。 |
5120 |
TP |
张量并行度 (Tensor Parallelism): 模型张量分解的并行数,通常用于跨设备分解计算。 | 8 |
PP |
流水线并行度 (Pipeline Parallelism): 模型分层的并行数量,用于流水线并行。 | 2 |
公式与关系
全局批量大小 (GBS) 公式:
$\( \[ GBS = MBS \times \text{卡数} \times \text{梯度累积步数} \] \)$并行设置规则:
$\( \[ TP \times DP \times CP = \text{总卡数} \] \)$ 其中:TP: 张量并行 (Tensor Parallelism)DP: 数据并行 (Data Parallelism)CP: 检查点并行 (Checkpoint Parallelism)
总训练步数计算: $\( \[ \text{训练迭代数 (Train Iters)} = \frac{\text{数据集大小}}{\text{GBS}} \times \text{EPOCH} \] \)$
优化器与调度器相关参数
LR和MIN_LR一起决定了学习率的范围。学习率通常通过预设调度器(如
cosine decay)逐步衰减到MIN_LR。
示例配置
以下为实际的训练参数示例:
CP=1
DATA_TYPE=GeneralInstructionHandler
EPOCH=1
GBS=64
LR=1.25e-6
MAX_PE=4096
MBS=1
MIN_LR=1.25e-7
MODEL_NAME=yi-34b
MOUNT=OBS
TRAIN_ITERS=1400
RUN_TYPE=sft
SAVE_INTERVAL=1400
SEED=1234
SEQ_LEN=4096
SN=5120
TP=8
PP=2
并行设置规则:
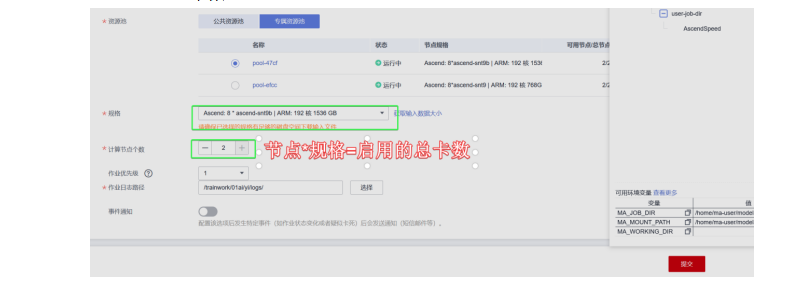
TP * DP * CP = 总卡数
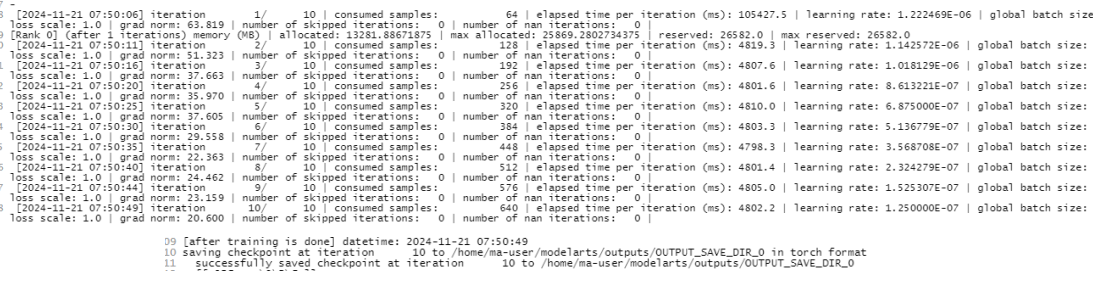
训练日志: