大模型推理
大模型推理提供多种方案,MindFormers/MindIE,请根据具体需求选择。
随着千亿级参数大模型 DeepSeek R1 的突破性发展,其创新的架构与海量参数规模对分布式推理提出了更高要求。 为应对算力挑战、提升推理效率,华为昇腾 MindIE 推理引擎率先推出 DeepSeek R1 多机分布式推理解决方案,通过动态并行调度、显存优化及昇腾芯片级加速技术,显著降低端到端推理时延,支撑超大规模模型的高效部署。
特开设专题,将深入剖析 MindIE 多机推理 DeepSeek R1 模型的关键技术路径,结合实测性能数据与场景化案例,为行业提供大模型分布式推理的昇腾实践范本。
vllm
获取运行环境
## 获取镜像
wget http://39.171.244.84:30011/vllm/vllm-ascend-v0.7.3rc1.tar.gz
docker load -i vllm-ascend-v0.7.3rc1.tar.gz
## 查看镜像ID
docker images ##找到IMAGE ID,例:3378ec1ab3d2
## 启动容器
docker run -itd --name=vllm_test --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /home/models:/home/models \
3378ec1ab3d2
## 查看容器ID
docker ps ##找到CONTAINER ID,例:087600cb50fa
## 进入容器
docker exec -it 087600cb50fa bash
启动容器:
--device参数可以继续添加挂载卡,例:--device=/dev/davinci2来添加第三张卡
起服务
vllm serve Qwen2_5-VL-7B-Instruct \
--dtype bfloat16 \
--max_model_len 32768 \
--max-num-batched-tokens 32768 \
--gpu-memory-utilization 0.95 \
--tensor-parallel-size 2
注:qwen2.5-vl-7b-ins默认上下文为128000,不手动设置max_model_len会导致oom
回显如下表示服务部署成功
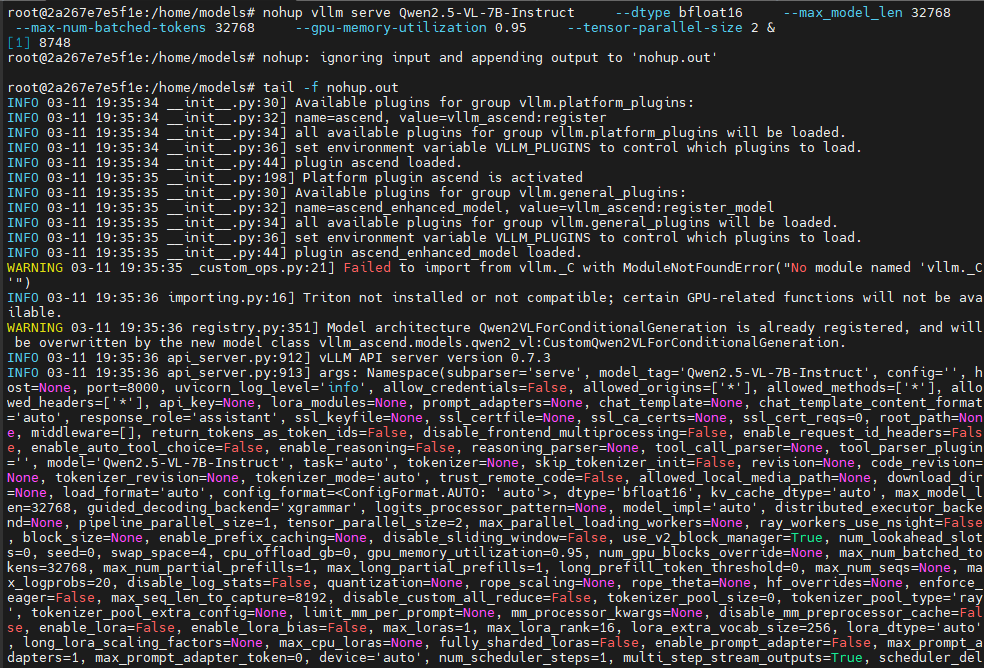
请求
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2.5-VL-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/qwen.png"}},
{"type": "text", "text": "What is the text in the illustrate?"}
]}
]
}'

benchmark
python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model Qwen2_5-VL-7B-Instruct --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
–dataset ShareGPT_V3_unfiltered_cleaned_split.json:这个参数指定了用于测试的数据集
–profile:启用性能分析。意味着在运行测试时会收集性能相关的数据,如内存使用情况以及处理请求所需的时间。
MindIE
MindIE(Mind Inference Engine,昇腾推理引擎)是昇腾针对AI全场景业务的推理加速套件。通过分层开放AI能力,支撑用户多样化的AI业务需求,使能百模千态,释放昇腾硬件设备算力。MindIE提供了基于多种AI场景下的推理解决方案,具有强大的性能、健全的生态,帮助用户快速开展业务迁移、业务定制。
查看MindIE模型支持列表: MindIE支持模型列表
1.环境准备
建议使用最新tag的镜像:镜像获取
安装MindIE使用镜像配套脚本:
chmod +x mindie_new.sh使脚本可执行bash mindie_new.sh一键安装
2.修改配置
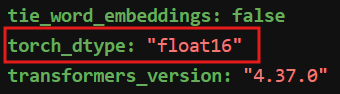
修改模型配置,在Huggingface模型权重的config.json文件中进行修改(参考中数据类型"float16"/"bfloat16")
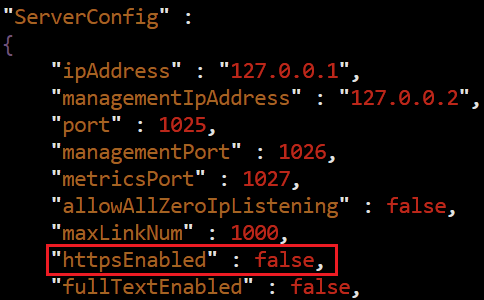
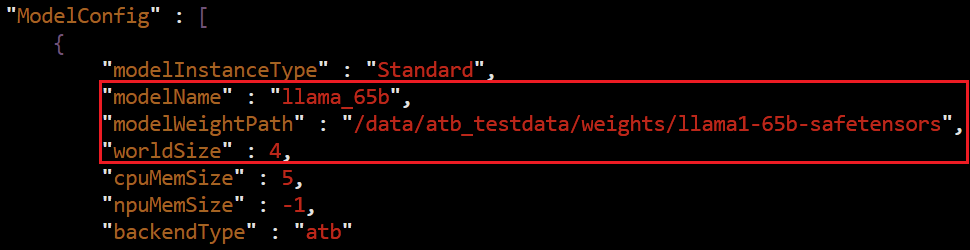
修改MindIE-service配置,MindIE工作目录位于 /home/ma-user/Ascend/mindie/latest/mindie-service 下。 想要启动服务,需要修改配置文件。
进入MindIE的配置文件
vim conf/config.json

3.启动MindIE
在MindIE工作目录下启动服务:.bin/mindieservice_daemon
回显Daemon start success!则说明启动成功
4.http请求测试
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"inputs": "大模型",
"parameters": {
"best_of": 1,
"decoder_input_details": false,
"details": false,
"do_sample": true,
"max_new_tokens": 500,
"repetition_penalty": 1.03,
"return_full_text": true,
"seed": null,
"stop": [
"photographer"
],
"temperature": 0.5,
"top_k": 10,
"top_n_tokens": 5,
"top_p": 0.95,
"truncate": null,
"typical_p": 0.95,
"watermark": true
},
"stream": false}' http://127.0.0.1:1025/
5.Gradio内网穿透
首先确保启动MindIE服务
执行Gradio_chat脚本文件,会返回一个公共链接

网页输入返回的公共链接,即可打开Gradio界面
6.性能精度测试
(1)数据集获取
GSM8K / CEval / MMLU / BoolQ / HumanEval
支持精度测试的数据集: GSM8K、CEval和MMLU
(2)依赖包安装
pip install jsonlines pyarrow prettytable
(3)性能测试
benchmark \
--DatasetPath "/{数据集路径}/GSM8K" \
--DatasetType "gsm8k" \
--ModelName "Qwen1.5-7B" \
--ModelPath "/{权重路径}/Qwen1.5-7B" \
--TestType client \
--Concurrency 100 \
--Http http://127.0.0.1:1025 \
--MaxOutputLen 512
--DatasetType 数据集类型,枚举值:ceval、gsm8k、boolq、humaneval和mmlu。--Concurrency 并发数,限制同时发起的连接数
性能测试结果主要关注FirstTokenTime、DecodeTime等token生成时延的指标和lpct(latency per compelete token,prefill阶段平均每个token时延)、Throughput等测试吞吐量的指标。
FirstTokenTime:首个token时延
DecodeTime:Decode阶段时延
Icpt:首token总时延/输入总token数。单位(ms)
Throughput:整体测试过程的每秒请求数,吞吐量指标。单位(req/s)
(4)精度测试
benchmark \
--DatasetPath "/{数据集路径}/GSM8K" \
--DatasetType "gsm8k" \
--ModelName "Qwen1.5-7B" \
--ModelPath "/{权重路径}/Qwen1.5-7B" \
--TestType client \
--Concurrency 100 \
--Http http://127.0.0.1:1025 \
--MaxOutputLen 512 \
--TestAccuracy True
--TestAccuracy True 参数是开启精度测试的开关返回的accuracy字段为精度测试结果
(5)参数说明
6.停止服务
查看与mindieservice相关的进程列表ps -ef | grep mindieservice查询mindieservice_daemon主进程ID

执行kill {主进程ID}即可停止服务
参考文档链接: 参考文档
MindFormers
MindSpore Transformers(MindFormers)套件的目标是构建一个大模型训练、微调、评估、推理、部署的全流程开发套件,该套件基于MindSpore内置的并行技术和组件化设计,提供业内主流的Transformer类预训练模型和SOTA下游任务应用,涵盖丰富的并行特性。期望帮助用户轻松的实现大模型训练和创新研发。
1.基础准备
建议使用最新tag的镜像:镜像获取
版本匹配关系:MindFormers r1.2.0
数据集获取:预训练-Wikitext-103 / 微调-alpaca
2.套件安装
chmod +x mindie_new.sh使脚本可执行bash mindie_new.sh一键安装
3.权重转换
3.2 权重转换
注: 请安装convert_weight.py依赖包。
pip install torch transformers>=4.37.2 transformers_stream_generator einops accelerate
3.2.1 torch权重转mindspore权重
将huggingface的权重转换为完整的ckpt权重。
python research/qwen1_5/convert_weight.py \
--torch_ckpt_dir /{权重文件路径}/Qwen1.5-7B \
--mindspore_ckpt_path /{权重转换输出路径}/qwen1.5_7b.ckpt
torch_ckpt_dir:预训练权重文件所在的目录, 此参数必须mindspore_ckpt_path:转换后的输出文件存放路径
如遇报错:
ImportError: {报错文件路径}: cannot allocate memory in static TLS block,使用LD_PRELOAD环境变量指定对报错的单个或多个库文件进行优先加载:执行Export LD_PRELOAD=$LD_PRELOAD:{报错文件路径}
3.2.2 mindspore权重转torch权重
在生成mindspore权重之后如需使用torch运行,可根据如下命令转换:
python research/qwen1_5/convert_reversed.py \
--mindspore_ckpt_path /{mindspore权重路径}/qwen1.5_7b.ckpt \
--torch_ckpt_path /{权重转换输出路径}/your.bin
mindspore_ckpt_path:待转换的mindspore权重路径torch_ckpt_path:转换后的输出文件存放路径
4.推理
注意事项:
Atlas 800T A2上运行时需要设置如下环境变量,否则推理结果会出现精度问题。
export MS_GE_TRAIN=0
export MS_ENABLE_GE=1
export MS_ENABLE_REF_MODE=1
4.1 单卡推理
python research/qwen1_5/run_qwen15.py \
--config predict_qwen1_5_7b.yaml \
--load_checkpoint /{mindspore权重路径}/qwen1.5_7b.ckpt \
--vocab_file /{权重文件路径}/Qwen1.5-7B/vocab.json \
--merges_file /{权重文件路径}/Qwen1.5-7B/merges.txt \
--run_mode predict \
--use_parallel False \ 是否开启并行
--auto_trans_ckpt False \
--predict_data '帮助我制定一份去上海的旅游攻略' #推理内容
推理命令中参数会覆盖yaml文件中的相同参数
4.2 多轮对话单卡推理
run_qwen1_5_chat.py 基于model.generate()实现,支持交互式多轮对话,支持加载lora权重、权重转换、多卡推理,暂不支持 batch 推理。
在predict_qwen1_5_7b_chat.yaml配置词表文件vocab.json和merges.txt的路径
python research/qwen1_5/run_qwen1_5_chat.py \
--config predict_qwen1_5_7b_chat.yaml \
--load_checkpoint /{mindspore权重路径}/qwen1_5_7b_chat.ckpt \
--enable_history True \
--use_parallel False \
--auto_trans_ckpt False \
--run_demo True \
--device_id 0
--enable_history: 是否将历史对话带入后面的输入。在交互式模式下(且启动时指定了–enable_history=True),可以用 /clear 清除前面的对话历史,开始新一轮会话--run_demo: 启动时是否自动运行预设的若干个问题(用于演示/试验目的)--predict_data: 提交给模型进行推理的问题(run_qwen1_5_chat.py会将历史对话和问题按照chatml格式组装后提交给模型进行推理),可以给出多个问题。不给出此参数时,run_qwen1_5_chat.py按交互模式运行